Today, I want to share a really handy feature in Ubuntu,
Startup Application. Startup Application allows you to run additional script or program during the operating system startup. The use case that it can help you are numerous. From mount your drives or devices, startup your development web server, or maybe more complex repetitive tasks that you need to run manually every time you sign into your Ubuntu.
I will show a use case that I personally use in my Ubuntu and this is will be very helpful if you fresh install Ubuntu in your laptop. The use case is to enable edge scrolling and two finger scrolling on your laptop's
Synaptics Touchpad. To enable those two features you need to run following commands in your terminal (to open your terminal press
ctrl + alt + t):
$ synclient VertEdgeScroll=1
$ synclient VertTwoFingerScroll=1
If you run those commands you can see that they work perfectly enabled your edge scrolling and two finger scrolling. But the problem is the effect of those commands will wear off every time you restart/shutdown your computer so you need to run those commands again and again. This is the time for Startup Application will help you!
Ok, here is how I use Startup Application:
First Step:
1. Create a bash script called
scrolling inside /bin/ directory by running following command in your terminal:
$ sudo gedit /bin/scrolling
2. That command will open a text editor and you need to copy this as its content:
#!/bin/bash
synclient VertEdgeScroll=1
synclient VertTwoFingerScroll=1
3. Save and close that file.
Second Step:
Make sure you change the type of that
scrolling file into excutable using this command:
$ sudo chmod +x /bin/scrolling
Last Step:
1. Open Startup application from Ubuntu Start menu.
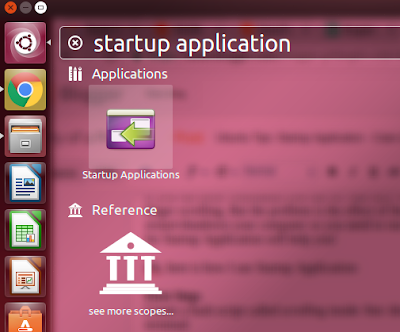 |
| Open Startup Application in Ubuntu |
2. Once opened you will see something like this.
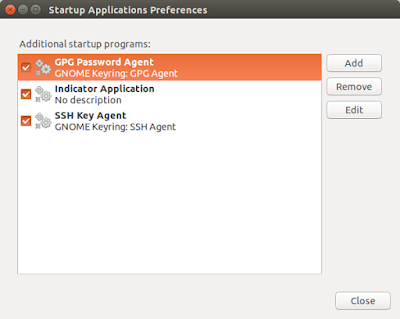 |
| View of Startup Application Preferences |
3. Click "Add" and enter the following information as in the image below then click "Add".
Name: Scrolling
Command: /bin/scrolling
Comment: Enable two fingers scrolling and edge scrolling
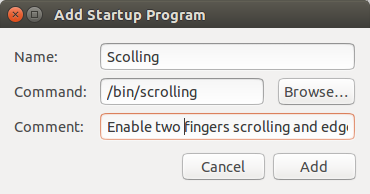 |
| Add Startup Program |
4. Close the Startup Application
That's all you have to do, it's easy and you can try restart your computer to see the result. :D
If you find this is helpful or do you have something in mind you want to try with Startup Application? Please share your experience in the comment. Thank you :)







